The Modern Data Stack Is Dead. Who Killed It?



TL;DR The modern data stack (ETL + warehouses + orchestration tools) is breaking down. AI can now write transformations and queries. The new bottleneck is running that code safely, at scale. Fused is a serverless execution layer for data and AI workflows.
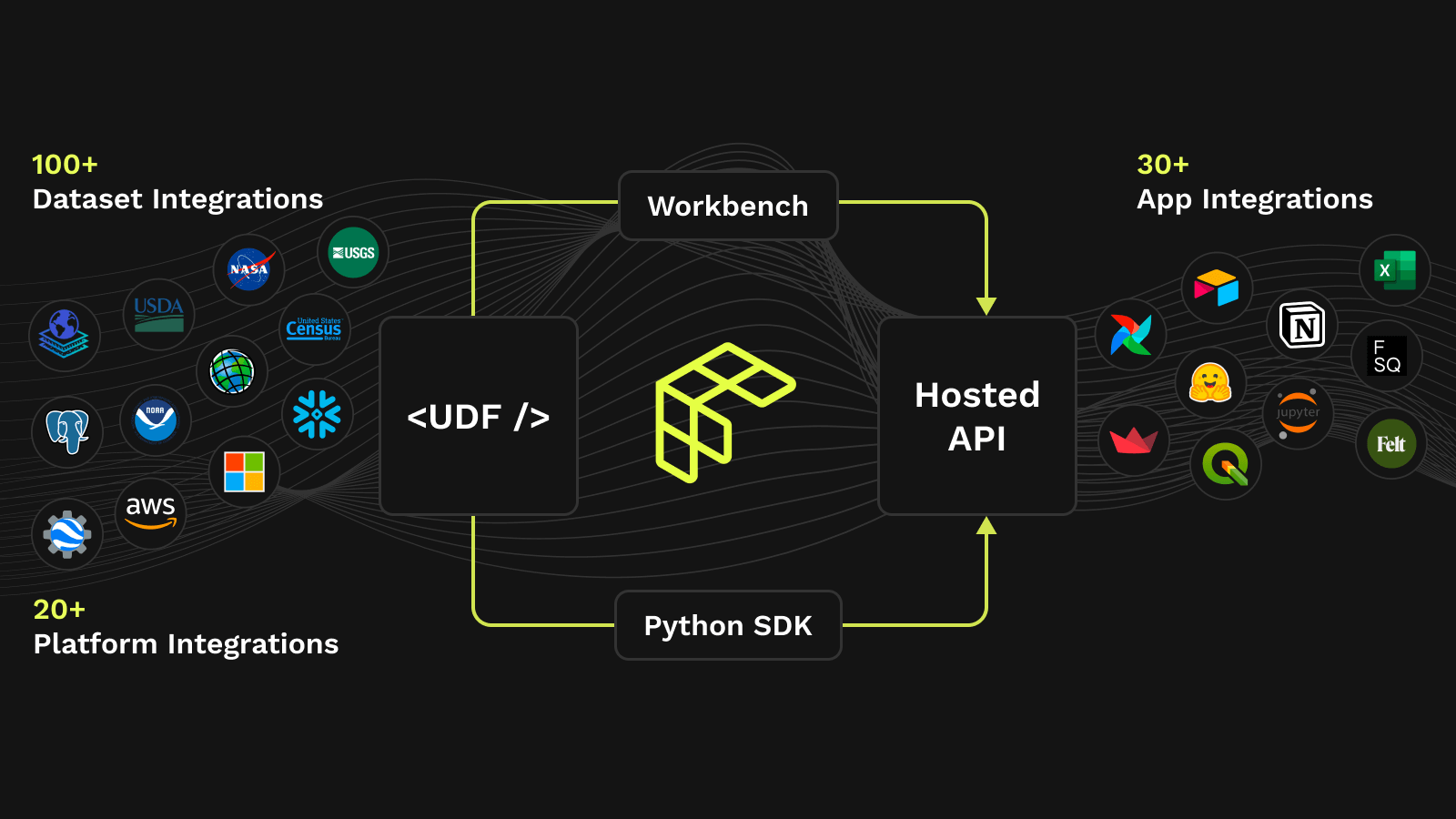
Fused is a serverless execution layer for data and AI workflows. With Fused, teams can write simple Python functions and run them at scale—directly on their data—without having to manage any infrastructure.
We have a murder on our hands.
The victim? The modern data stack. For years, data teams have relied on a patchwork of tools: ETL pipelines, warehouses, orchestration layers, and dashboards. Getting anything done often meant stitching together 5-6 different systems just to move and transform data. Something changed. The modern data stack wasn’t killed by one company or project. It was replaced by a shift across the entire ecosystem. We've rounded up the suspects as to who may have been at the scene of the crime, and we're going to round them up one after the other.