DuckDB, Fused, and your data warehouse

GLS (General Logistics Systems) is an international parcel delivery service provider, primarily operating in Europe and North America. To stay ahead in the fast-paced logistics industry, GLS launched GLS Studio—an innovation lab aimed at optimising and modernising its depots and processes through cutting-edge technology.
Stefano co-founded GLS Studio to build the next generation of data-driven products. In this post, he shares how GLS Studio uses Fused to drive efficiency and innovation in parcel delivery.
In this blog post, Stefano shows how his team powers GLS's ParcelPlanner app, which helps GLS evaluate delivery routes efficiently. The app uses Fused to query Snowflake and serve H3-partitioned geospatial data to the frontend, which is powered by Honeycomb Maps and DuckDB WASM.
Querying Snowflake
At GLS Studio, we faced a challenge when querying Snowflake to serve H3-partitioned geospatial data for our map frontend - which is powered by Honeycomb Maps and DuckDB WASM. While precomputing Parquet files seemed like the most straightforward solution—which is the case for companies already equipped with a data lake and necessary tooling—it wasn't ideal for us because our existing applications required most of the data to remain warehoused in Snowflake. This forced us to become creative about finding a solution that could maintain Snowflake as our primary data warehouse while avoiding the inefficiencies of precomputing files and reduce query costs without compromising performance.
To address this, we needed to tackle three key issues:
- File-based Output: Serving data to DuckDB on the frontend required loading it from remote file endpoints. Switching to a traditional REST API would have added unnecessary complexity.
- Performance: Updating data based on user interactions required querying the database with minimal latency.
- Cost: Repeated queries to Snowflake were prohibitively expensive, making it crucial to find a more cost-effective approach.
Using Fused, we found a solution that bridged the gap between our client applications and our data warehouse seamlessly. Fused's User Defined Functions (UDFs) enabled us to read from Snowflake and deliver data behind remote Parquet file endpoints for DuckDB to consume directly and render on the Honeycomb map.
The Power of Caching
Additionally, to avoid straining on our Snowflake cluster (or breaking the bank), we leverage Fused's built-in caching mechanism. This ensures that repeated queries are efficiently handled without draining resources.
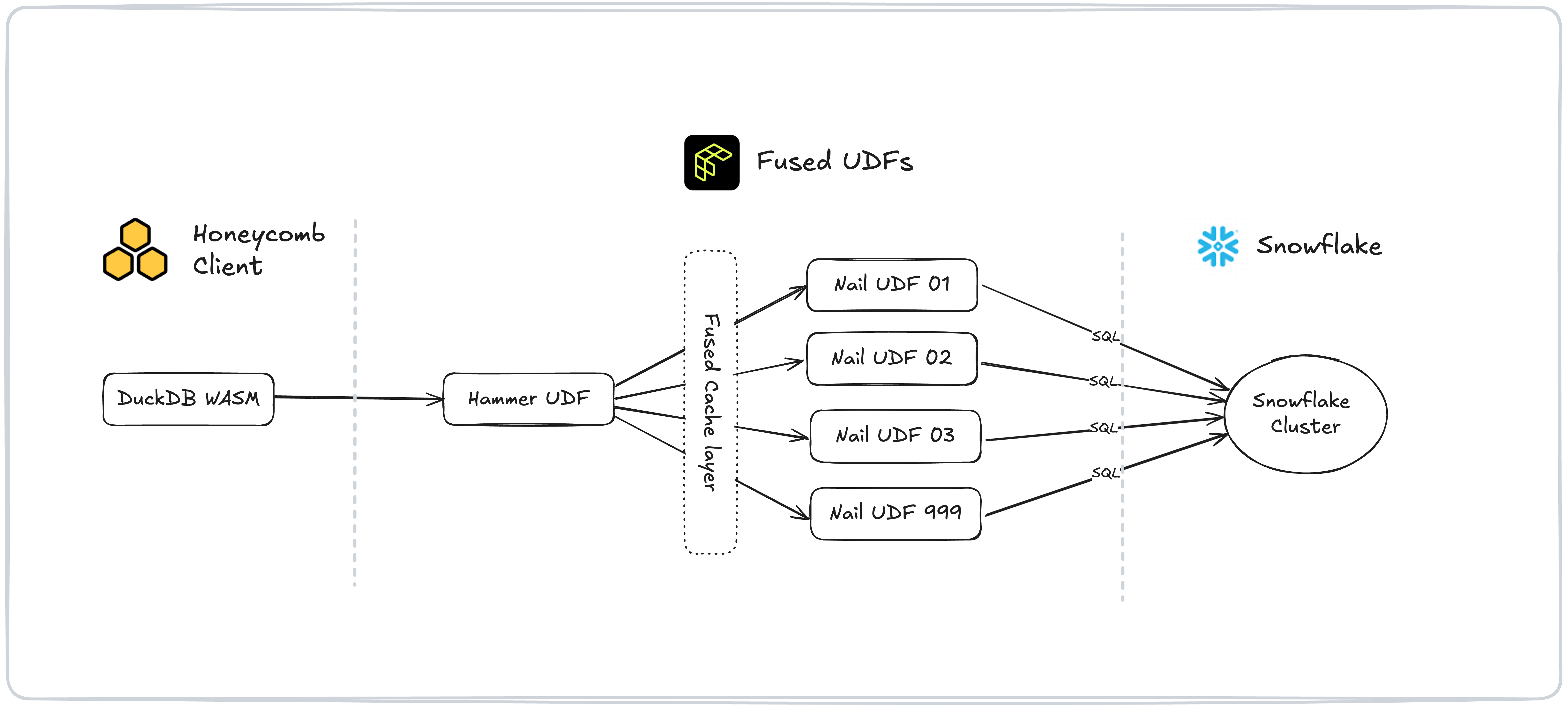
We then created two key UDFs within Fused. These work in tandem to handle authentication, caching, and efficient data retrieval for our DuckDB-powered map:
- The "Public" UDF (Hammer): This UDF isn't cached and serves as the entry point. It handles authentication and collects the full date range requested by the customer.
- The "Private" UDF (Nail): This cached UDF takes a single date and returns the necessary data for that specific day.
The "Hammer" UDF spawns up to 1,000 asynchronous Fused workers, each running an instance of the "Nail" UDF to fetch data for an individual date, as specified with a parameter. Once the data is retrieved, it is stitched together into a single GeoPandas DataFrame, ready for use.
With this approach, historical data only needs to be read once from Snowflake. For the present date, which is subject to updates, we handle caching differently and apply a one-hour cache to optimise performance.
Conclusion
In the end, Fused allowed us to integrate our Honeycomb maps directly with Snowflake, handling caching and security concerns. This approach saved us significant backend development and data engineering work—all with just a few dozen lines of Python.