DuckDB + Fused: Fly beyond the serverless horizon


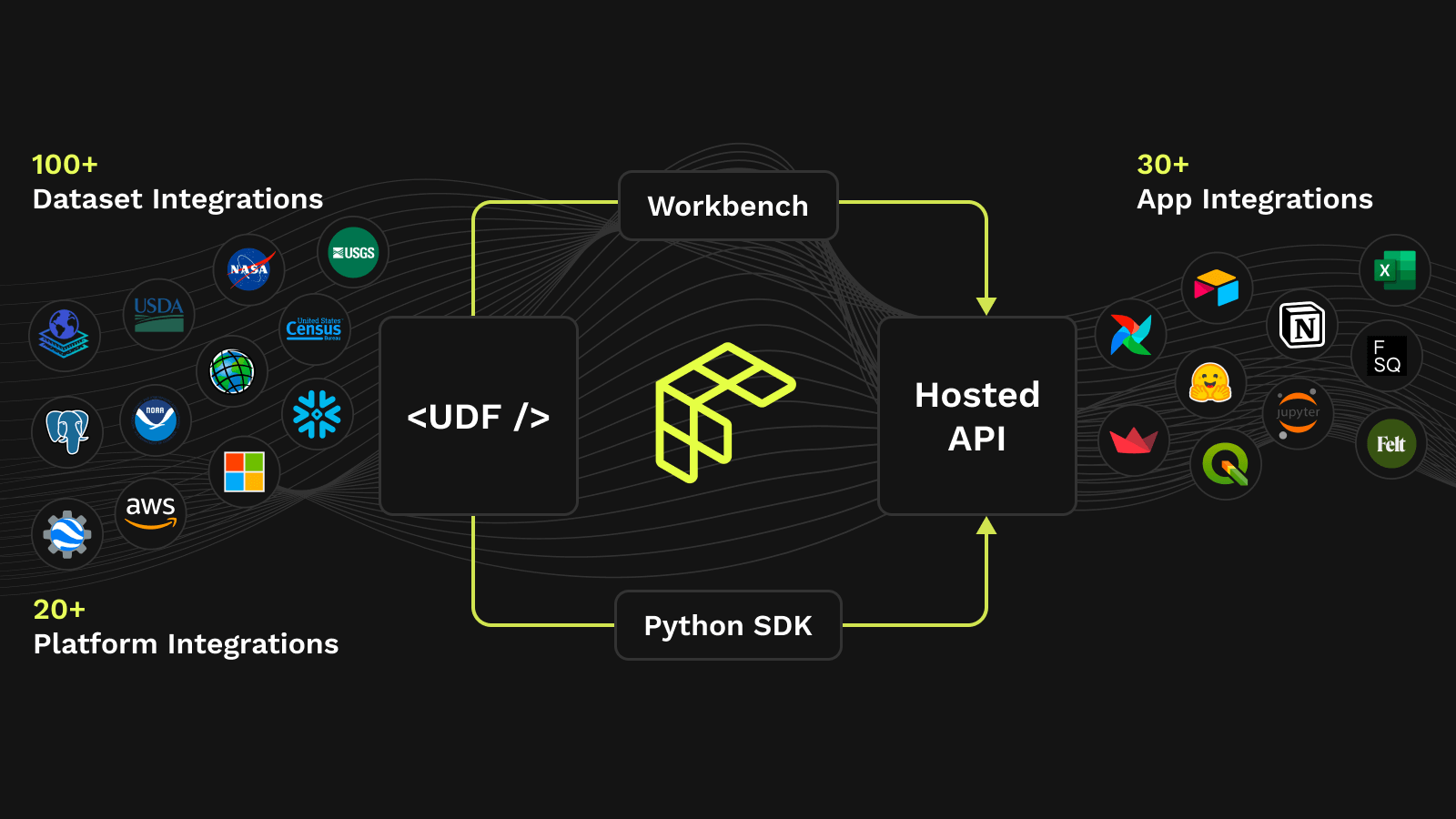
The combination of Fused serverless operations and DuckDB offers blazing fast data processing. Fused embraced Python to create serverless User Defined Functions (UDFs). Now, with the help of DuckDB, Fused enables developers to leverage the ease and familiarity of SQL in these functions - without compromising performance and parallelism.
This blog explains how Fused User-Defined Functions (UDFs) can extend DuckDB to bring quick serverless operations on any scale dataset. The result is a lightweight, portable, and flexible system that is simultaneously scalable, cost-efficient, and simple to integrate across the stack.
The blog post illustrates three complimentary implementations:
The evolution of the data processing landscape
For companies with bottom lines that depend on time to insight, the data landscape is driven by the need to process increasing data volumes and make operations easier to express. This section discusses how Fused and DuckDB can address these needs within the context of the latest wave of the data processing ecosystem.
Increasing data volumes
When the size of data required for an operation is larger than memory, it becomes a bottleneck. In the early 2010's, the effort to process increasing volumes of data created MapReduce, Hadoop, and Spark to help companies scale out clusters. The complexity of managing clusters gave way to managed services like Databricks and Snowflake, but their high cost and inefficient data transfer with Python (by now a staple of data science) still left parts of the market unaddressed.
Many technologies emerged to attempt to address latent gaps, but it was DuckDB that surged around 2020 as a fast, easy to use, and cost effective solution to process large volumes of data with SQL while reducing the switching cost of having to learn new frameworks. At around the same time, serverless solutions to address the scale out problem started to gain traction.
Now, as AI training and inference require ever more data, the speed of processing and the speed of development become critical bottlenecks. DuckDB and serverless processing together enable new applications. DuckDB gives workflows an in-process performant SQL engine with:
- Fast processing of large datasets through larger than memory processing with a vectorized query engine.
- Zero-copy interoperability with Python, thanks to formats like Apache Arrow.
- Portability and unprecedented developer experience with easy set-up and without the need to maintain a database server.
- Extensibility thanks to an ecosystem of plugins and extensions (C++), scalar Python UDFs, and WebAssembly compatibility.
DuckDB's modularity in data interchange and query execution makes it an ideal choice for serverless architectures. The combination of DuckDB and serverless has unique advantages:
- Fast and cheap data access thanks to cloud optimized data formats that enable retrieving part of the file (e.g. Parquet for tabular data, Cloud Optimized GeoTIFF for imagery.)
- Scalability, distributed compute without managing infrastructure and without expense when code is not running.
- Easy to share results and create integrations by triggering jobs and loading data via simple HTTP calls.
Python + SQL synergy
Python is the lingua franca of data science and AI. It's an imperative language - which means it's easy to write complex logic without sacrificing readability, and interface a broader range of data formats - enabling operations inaccessible to SQL like calling API clients, fine-grained analytic calculations, and processing arrays and rasters. The Python ecosystem recently adopted Rust to write high performance, memory safe modules. However, Python historically struggled with concurrency and managing the memory of distributed clusters, which hindered its ability to process large datasets.
Declarative languages like SQL offer simple syntax to define data manipulations for performant query engines, but they lack explicit control flow and are limited to select data structures.
Two approaches to intertwine SQL and Python emerged, each with particular tradeoffs in portability and efficiency:
- SQL queries in Python. These tend to sacrifice data transfer efficiency between runtimes or require specialized, complicated data warehousing.
- Python UDFs within SQL. These tend to incur performance costs and require maintaining a Python runtime within the DBMS.
These are offered, to different extents, by tools like Databricks, BigQuery, and Postgres.
- Databricks offers a notebook environment, familiar to the data scientist, that enables workflows to transition between Python and SQL - but requires specialized data warehousing, complicated cluster management, and lacks debuggability.
- BigQuery UDFs bring an imperative language to SQL engine - but it's constrained to Javascript which lacks Python's powerful data operations and libraries.
- Postgres and other databases can bring SQL to a Python runtime with connector libraries such as Psycopg2 and SQLAlchemy - but this pattern has the infrastructure overhead of needing to run a separate database server.
However versatile, DuckDB is founded on SQL and still needs to rely on Python and plugins for expressibility. But its support for Python UDFs and plugins is yet to mature.
- DuckDB only supports scalar Python UDFs.
- Constrained to the capabilities of the local runtime process.
- There's no seamless way to share Python UDFs across databases or runtimes.
- Plugins are difficult to write and deploy.
Fused + DuckDB synergy
Fused is a framework to author and run serverless operations. Every Fused UDF is an HTTP API that can be called to run and load data from any application that can make HTTP requests. Integrating UDFs into workflows is as easy as passing the endpoint as a string. Spreadsheets, web maps, ETL pipelines, and DuckDB can all load data from HTTP API endpoints, and dynamically parametrize calls with query parameters.
- Eliminates the need to provision, manage, and scale instances - which is what caused the initial break away from the Map Reduce, Hadoop, and Spark era. Its just-in-time backend scales from zero to cluster as quickly as needed.
- UDFs can call UDFs - which results in blazing fast execution by running thousands of parallel jobs -without worrying about orchestration.
- Pay only when code runs, and run from anywhere - which speaks to market segments unaddressed by managed platforms like Databricks and Snowflake.
- Natively runs on a standard Python interpreter - so it seamlessly runs DuckDB while keeping Python's expressibility and ecosystem of libraries.
- Dovetails with cloud-native data formats. Their atomic data loading and compressed formats make for reduced data transfer between local processes and third party cloud warehouses.
Fused and DuckDB together reduce architectural complexity and make it easy to have cutting-edge analytic processing in any application. Together, they eliminate the need for cumbersome distributed query engines which are slow to start-up and are overkill for smaller datasets.
Fused UDFs are easy to share and can run from anywhere. The examples in this post are available as community UDFs you can find on the open source Github repo and run them in any Python environment with the Fused SDK.
Example patterns
This section shows and discusses three powerful patterns at the intersection of Fused and DuckDB.
1. Run DuckDB in a Fused UDF
DuckDB parallelizes its own operations under the hood thanks to its columnar vectorized query engine that provides compelling performance for querying using SQL. However, there can still be bottlenecks in operations upstream or downstream of DuckDB. To resolve this, Fused UDFs easily run DuckDB and create a seamless experience between Python and SQL.
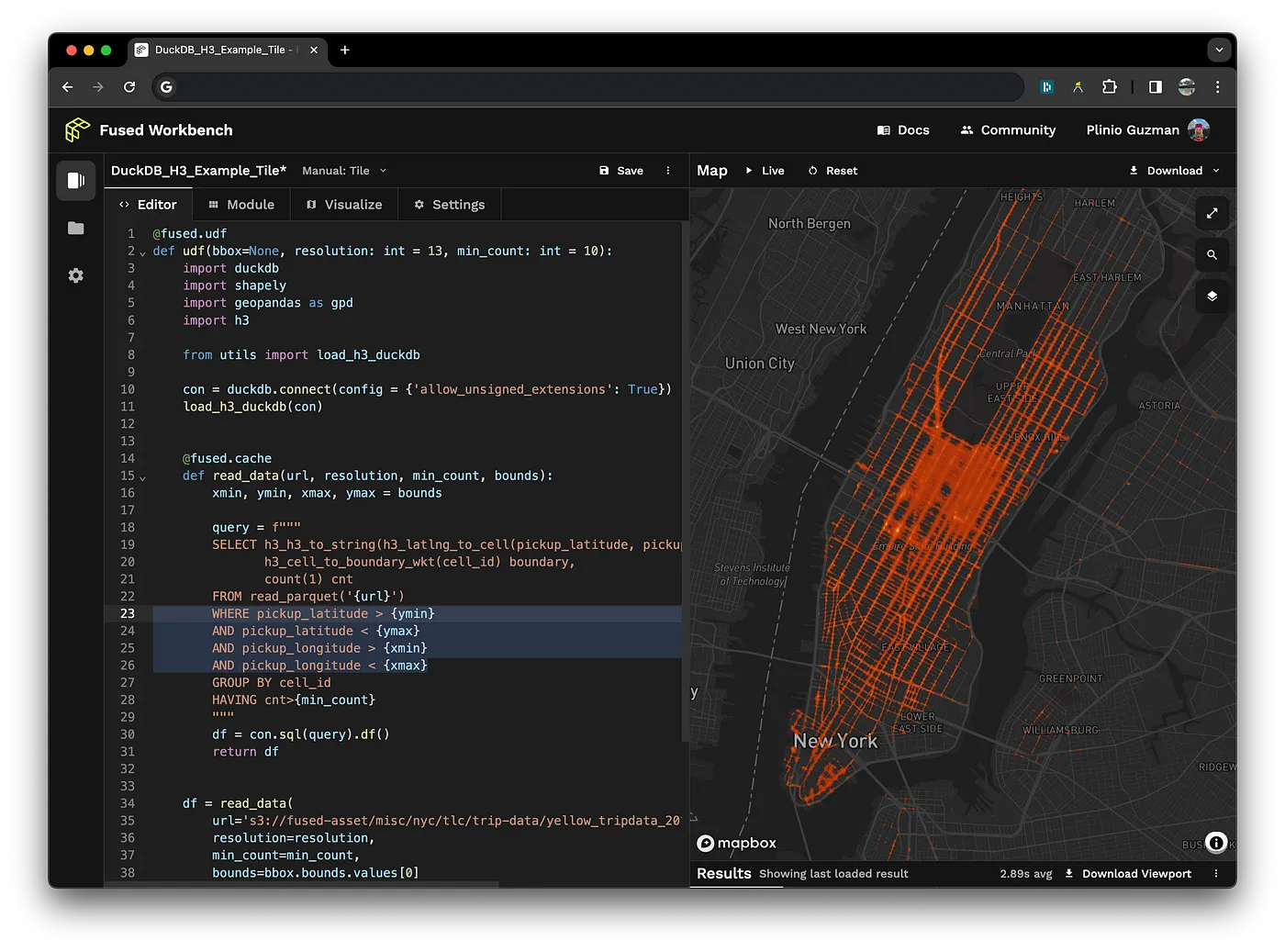
See the full example in the docs.
2. Call Fused UDFs from DuckDB
Any database that supports querying data via HTTP can call and load data from Fused UDF endpoints using common formats like Parquet or CSV. This means that DuckDB can dispatch operations to Fused that otherwise would be too complex or impossible to express with SQL, or would be unsupported in the local runtime.
In this example, a Fused UDF returns a table where each record is a polygon generated from the contour of a raster provided by the Copernicus Digital Elevation Model as a Cloud Optimized [GeoTIFF. DuckDB can easily trigger a UDF and load its output with this simple query, which specifies that the UDF endpoint returns a Parquet file.

This pattern enables DuckDB to address use cases and data formats that it doesn't natively support or would otherwise see high data transfer cost, such as raster operations, API calls, and control flow logic.
See the full example in the docs or open it in this DuckDB shell.
3. Integrate DuckDB in applications using Fused
Fused is the glue layer between DuckDB and apps. This enables seamless integrations that trigger Fused UDFs and load their results with simple parameterized HTTP calls.
DuckDB is an embedded database engine and doesn't have built-in capability to share results other than writing out files. As a corollary of the preceding example, it's possible to query and transform data with DuckDB and seamlessly integrate the results of queries into any workflow or app.

To try this example simply make a copy of this Google Sheets spreadsheet (File > Make a copy) and click, and modify the parameters in B2:4 to trigger the Fused UDF endpoint and load data.
See the full example in the docs.
Conclusion
While the pendulum of the data landscape swung from distributed compute to single-node, Fused's serverless operations swing the conversation back with a simple and cost-efficient scale-out.
This blog post discussed how gaps in the modern data stack can be addressed by integrating Fused and DuckDB, two emerging data processing tools. The intersection between DuckDB's portable SQL and Fused's scalable python operations creates a stack that is: Flexible due to the seamless interaction of Python and SQL. Scalable, simple, and cost efficient.
Easy for data scientists to create, and easy for non-coders to consume.
DuckDB is an early example of how Fused integrates with the modern data stack. We're eager to share the growing list of compelling integrations over the following months.
We would like to extend our thanks to Wes McKinney and Michael Driscoll for reviewing drafts of this post before it went out.
Get started with Fused
Want to get involved?
- If you'd like to take Fused for a spin, please sign up for the Private Beta waitlist.
- Give back to the community by contributing a UDF.
- You can also join the conversation by becoming a member of the Fused Discord community. We are always happy to hear your thoughts.
- Does taking serverless operations to the next level sound exciting to you? Fused is hiring! Shoot us a note at
sina@fused.io.